hana replication27 Jan 2015
本文主要介绍HANA的Replication和TakeOver的方式
相信很多的人都不陌生HANA,是SAP自主研发的内存级数据库,由于工作需要,前段时间做了一次hana的跨机房data center热切takeover,即使在SAP中国研究院内部也没有找到上T级别内存数据库的takeover经验,而且还是跨DC。历时1周,遇到各种问题,最终成功完成。
以下作为简述笔记,如有问题,可以留言给我,大家一起讨论。
机器准备
这里先介绍单机版replication,hana cluster的replication也类似,只是hana cluster master要与hana cluster slaver集群大小一致,hana cluster的构建将在接下来的文章中介绍。
在现有的hana数据库的基础上,准备一台hana slave机器,并且安装了hana的数据库,至少要64G的内存吧。 >hana slave的端口号必须与hana master的保持一致,例如30015。
如何安装hana数据库这里就不做赘述了。./hdbinst --ignore=check_hardware,check_diskspace
master机器操作
执行以下shell脚本
su - <sid>adm
./hdbnsutil -sr_enable --name=nice-name
./hdbnsutil -sr_state./hdbnsutil -sr_state将会显示出当前hana的replication状态
打开hana studio,然后修改监听端口,如下图:
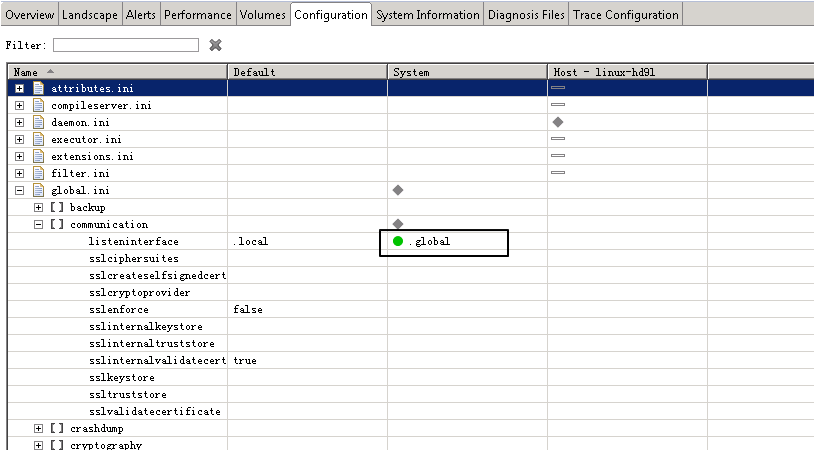
早期的hana版本要求主机名必须为全小写短名称,假设版本在73之前请使用
./hdbrename修改hana的文件名
slaver机器操作
停止slaver上的hana实例并注册replication 服务器
su - <sid>adm
/usr/sap/hostctrl/exe/sapcontrol -nr <instance_number> -function StopSystem HDB
hdbnsutil -sr_register --remoteHost=<master> --remoteInstance=00 --mode=async --name=<slave>
--mode=async为异步--mode-sync为同步
切换
在slaver机器上
hdbnsutil -sr_takeover如果时间比较长,需要耐心等待
此时slaver机器将变为master机器,如果想与原来的master机器现在的slaver机器断开连接,需要执行./hdbnsutil -sr_disable
